Data Science Consultant Role
Data Science has emerged as one the important fields in the last period, capable of providing organizations in different fields with methods to gain insights with their often vast collections of data.
Data Science Consultant most often uses machine learning or deep learning models in addressing the problems of their clients.
Typical machine learning include both supervised and unsupervised models. In supervised machine learning models approach the data science consultant has labelled data sets available about the domain of application. The data set in this case consists of values for a set of features, input variables and a target variable that we want to predict.
The purpose of a supervised machine learning model is to learn on instances of the data set with the goal of predicting value of target variable from features values on previously unseen examples.
If the target variable is categorical, e.g. customer will buy/not buy a product, then we are talking about a classification problem. If the target variable is continuous then the problem is known as a regression problem.
There are various different methods available to train a machine learning model for classification and regression problems:
– linear regression (Lasso, Ridge)
– logistic regression
– random forest
– support vector machines
– gradient boosting machines, LightGBM and XGBoost
– deep neural nets, convolutional neural networks, Long-Short Term Memory (LSTM)
Before selecting a particular machine learning model for the assigned problem, an important of a data science consultant is to perform initial data preparation, feature selection and feature engineering.
Initial data exploratory analysis and feature selection can involve many different things. We can e.g. compute Pearson correlations between numerical features or compute Cramer’s V to determine correlations between categorical features.
Categorical features can often be divided in nominal and ordinal features, with ordinal features those where we can define an order between values but cannot compute distance, e.g. euclid one, between different values. An example of an ordinal feature would be education levels: primary school, high school, university and similar.
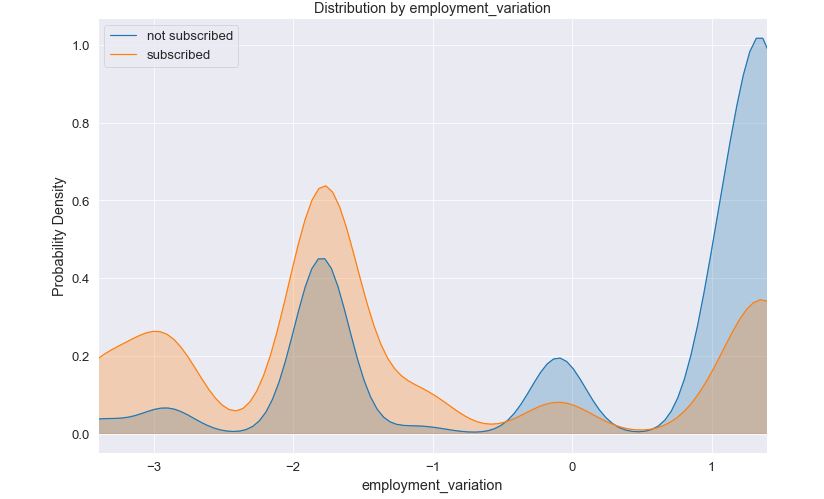
Another common analytical step for data science consultant is to generate Kernel Density Plots (KDE) which show how the values of a feature are distributed. Example plot:
Often useful are pairplots that show how features are interacting. Pairplots are often generated for a large number of features.
After initial exploratory data analysis one can continue with feature engineering. Although there are various definitions for this, we usually mean generating new features under feature engineering. One can generate new features by delving deeper in the domain of the problem. Fields like healthcare, telecom, finance often have different characteristics and specifics regarding have some typical variables affect others, e.g. interest rates of ECB and Fed on the behavior of clients when subscribing to financial products, like annuities and so on.
Feature engineering can take some time so there has been a lot of development in the field of automated feature engineering with featuretools an example of a very useful tool that helps in generating new features more quickly.
In initial data analysis, data engineers or machine learning engineers can provide a helpful role in preparing data for the data scientist.
After this first phase, the data science consultant then has to turn to the next one – building and training a machine learning model.